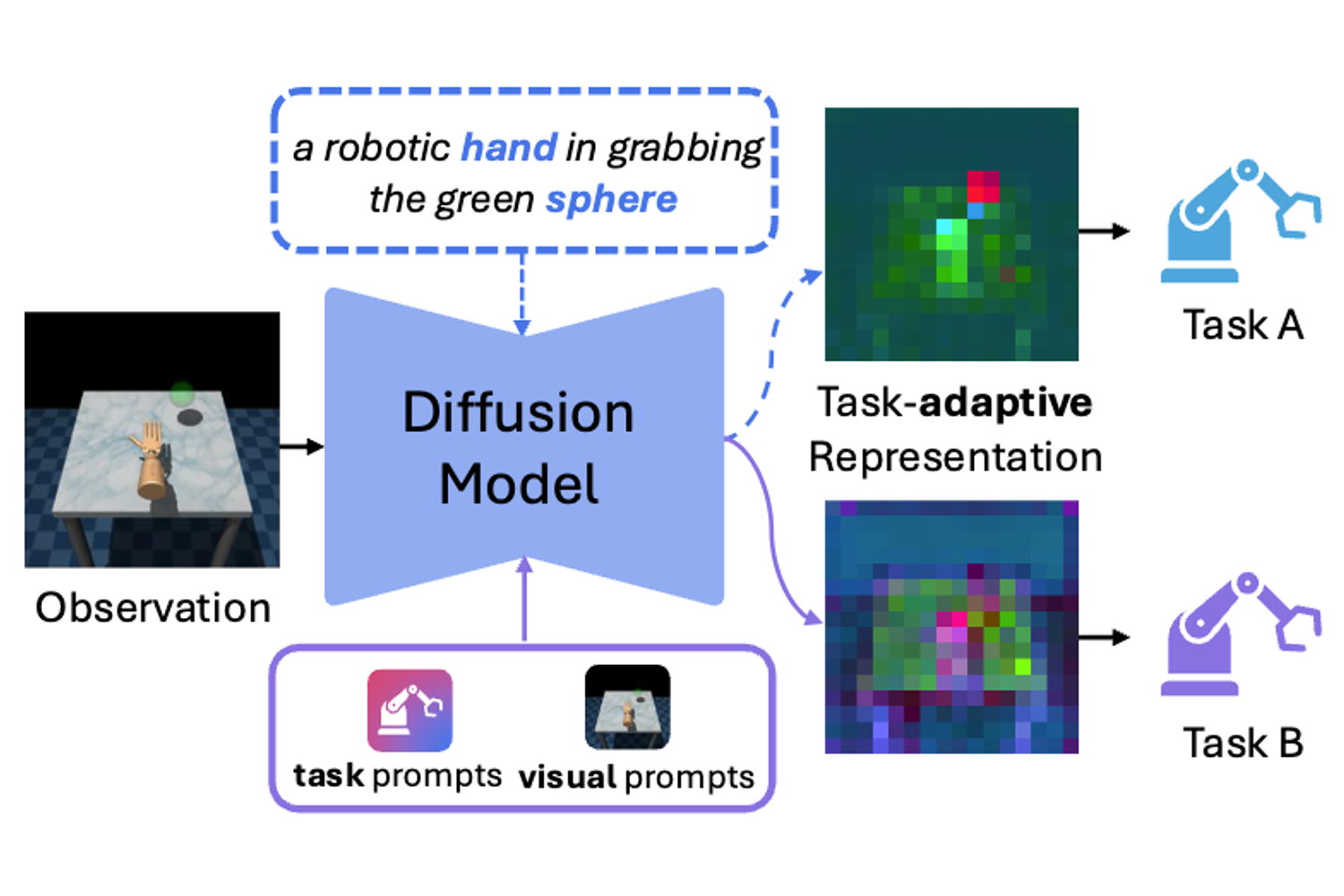
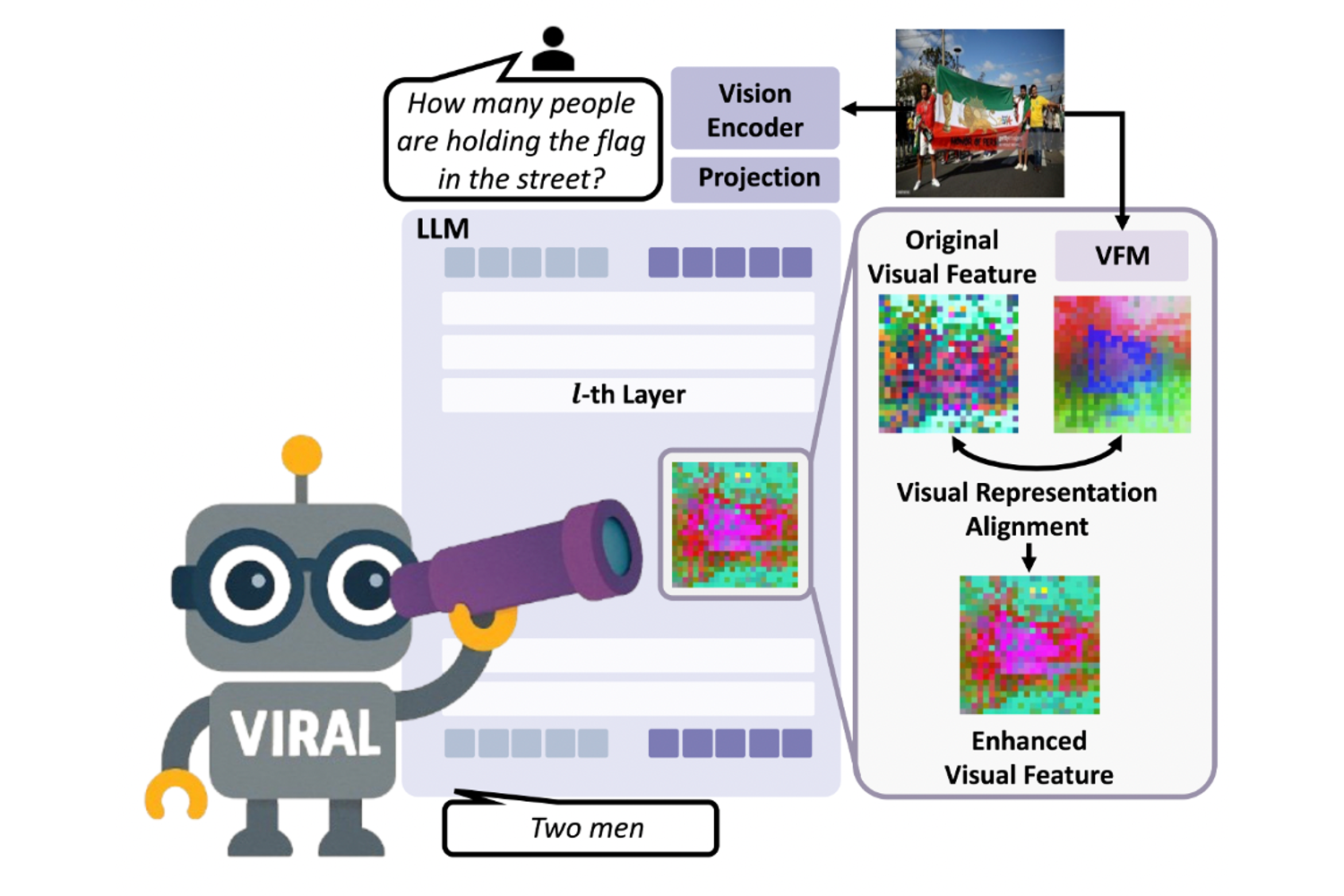
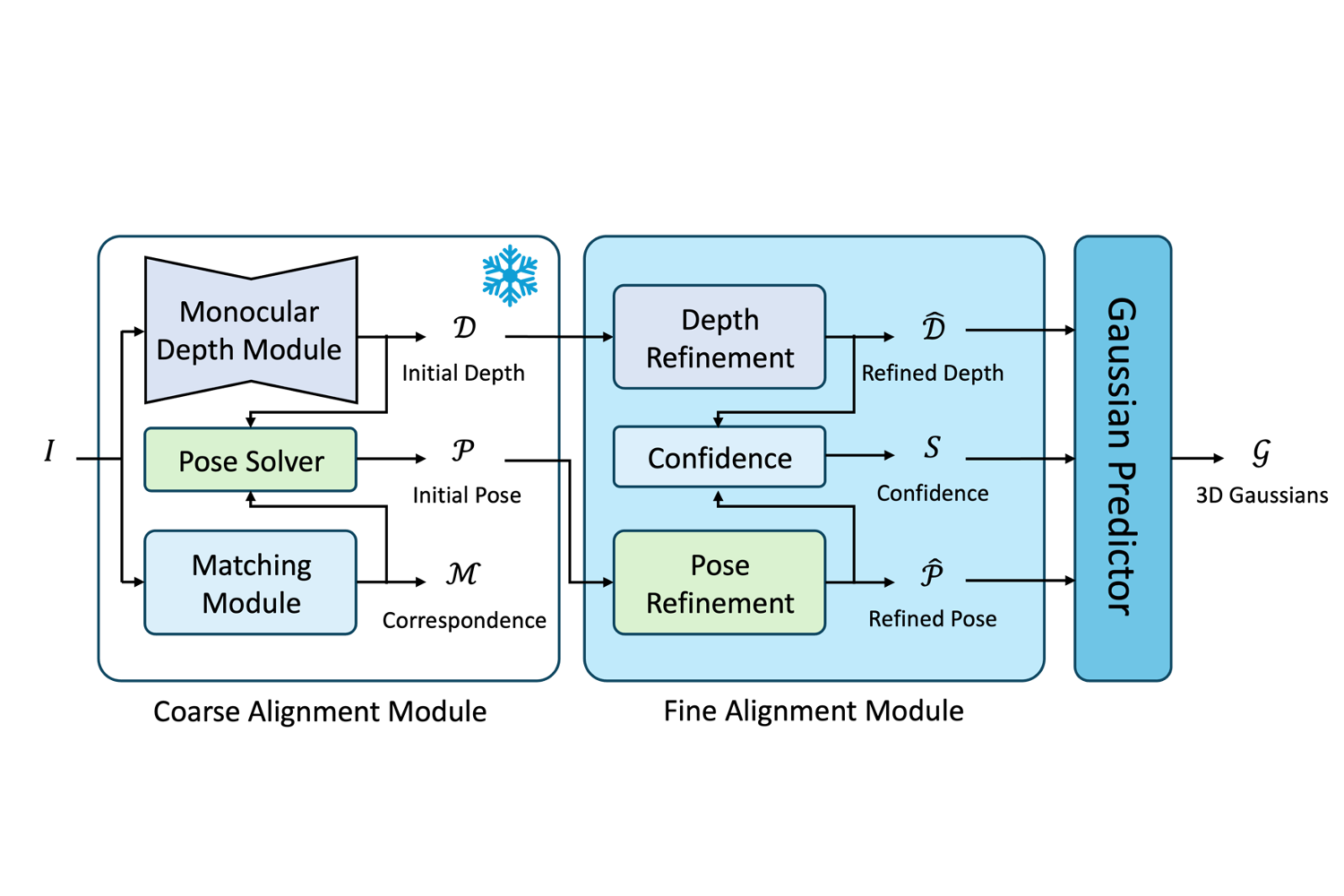
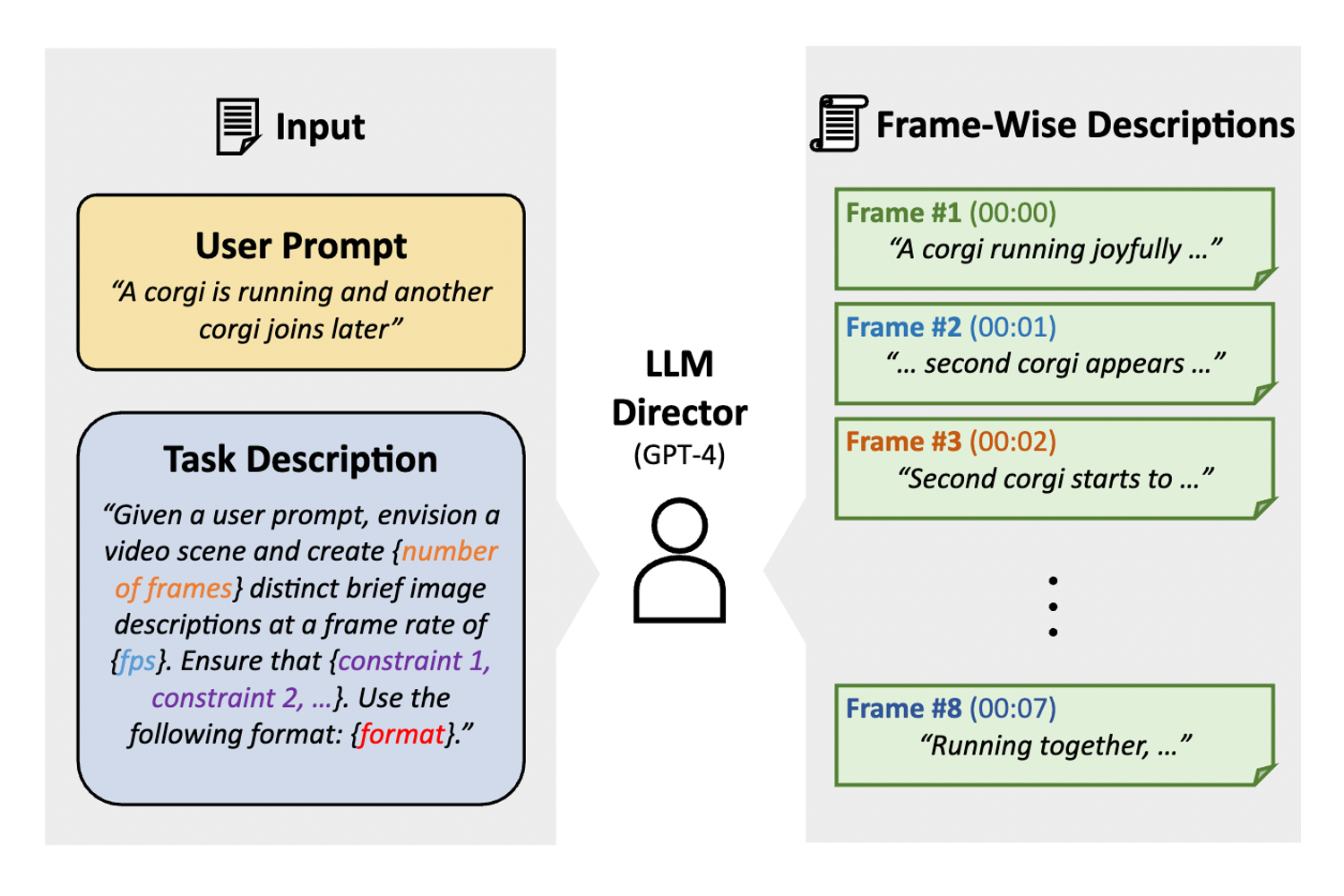
2026 CVPR Exploring Conditions for Diffusion models in Robotic Control Heeseong Shin, Byeongho Heo, Dongyoon Han, Seungryong Kim, and Taekyung Kim CVPR 2026 Page Paper 2025 Preprint Visual Representation Alignment for Multimodal Large Language Models Heeji Yoon*, Jaewoo Jung*, Junwan Kim*, Hyungyu Choi, Heeseong Shin, Sangbeom Lim, Honggyu An, Chaehyun Kim, Jisang Han, Donghyun Kim, Chanho Eom, Sunghwan Hong, and Seungryong Kim arXiv 2025 Page Paper NeurIPS Seg4Diff: Unveiling Open-Vocabulary Segmentation in Text-to-Image Diffusion Transformers Chaehyun Kim, Heeseong Shin, Eunbin Hong, Heeji Yoon, Anurag Arnab, Paul Hongsuck Seo, Sunghwan Hong, and Seungryong Kim NeurIPS 2025 Page Paper ICCV S4M: Boosting Semi-Supervised Instance Segmentation with SAM Heeji Yoon*, Heeseong Shin*, Eunbeen Hong, Hyunwook Choi, Hansang Cho, Daun Jeong, and Seungryong Kim ICCV 2025 Page Paper ICML PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting for Novel View Synthesis Sunghwan Hong*, Jaewoo Jung*, Heeseong Shin, Jisang Han, Jiaolong Yang, Chong Luo, and Seungryong Kim ICML 2025 Page Paper 2024 NeurIPS Towards Open-Vocabulary Semantic Segmentation Without Semantic Labels Heeseong Shin, Chaehyun Kim, Sunghwan Hong, Seokju Cho, Anurag Arnab†, Paul Hongsuck Seo†, and Seungryong Kim† NeurIPS 2024 Page Paper ICMLW Large Language Models are Frame-Level Directors for Zero-Shot Text-to-Video Generation Susung Hong, Junyoung Seo, Heeseong Shin, Sunghwan Hong, and Seungryong Kim First Workshop on Controllable Video Generation @ ICML 2024 Page Paper CVPR Highlight CAT-Seg: Cost Aggregation for Open-Vocabulary Semantic Segmentation Seokju Cho*, Heeseong Shin*, Sunghwan Hong, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim CVPR 2024, Highlight Presentation Page Paper CVPR Highlight Unifying Correspondence Pose and NeRF for Generalized Pose-Free Novel View Synthesis Sunghwan Hong, Jaewoo Jung, Heeseong Shin, Jiaolong Yang, Seungryong Kim, and Chong Luo CVPR 2024, Highlight Presentation Page Paper